
Newsletter April 2025: projects2
This month I’ve done a lot of programming. I ended up working more on my own code hosting platform. I call it projects2. Why two? Because it’s my second attempt at implementing this idea. Second attempt in recent times at least.
In my 2017 blog post, A new home for Timeline, I wrote
My suggested way forward is therefore to develop a new platform whose core features are registration free discussions and pull requests. In addition, it would need features common to many platforms like hosting of releases and a project web page.
In my previous attempt I focused on registration free discussions. This time, I decided to instead focus on creating the minimal possible software that allowed us to move away from SourceForge for Timeline and also get rid of the Jenkins instance that I run. That way, the infrastructure for running Timeline would not depend on proprietary systems or “complicated” third party software (Jenkins) which is overkill for our needs.
What follows is a demo of the current state of projects2.
Requirements
To use projects2 we need the following:
- A machine running Fedora Linux that we have root access to
- A domain that resolves to that machine
- An SSL certificate for that domain
I use DNSimple to purchase domains and SSL certificates and Linode to provision Fedora servers.
Initial setup
projects2 is implemented as a single Python script, projects2.py, which is
used to configure a single Fedora Linux machine to act as a code hosting
platform.
We configure our server in a config.ini file. Let’s use this for the demo:
[Global]
InstanceName = projectsdemo
Domain = projectsdemo.rickardlindberg.me
Title = A demo site for projects2.
Description = This site showcases the project2 code hosting platform.
[User:admin]
DisplayName = Rickard
SshKeys = <my public ssh key>
Projects = *
[WildcardCertificate]
pem = <my ssl certificate>
key = <my ssl private key>
Next we run the bootstrap command, which should only be run once on a fresh
Fedora install:
$ path/to/projects2.py bootstrap
ssh root login prompt
...
Ensuring user scm...
Ensuring passwordless sudo for scm...
Ensuring folder /home/scm/.ssh...
Ensuring authorized keys...
Ensuring folder /opt/projectsdemo...
Ensuring folder /opt/projectsdemo/web/artifacts...
Ensuring myself...
Ensuring myself api...
Ensuring config.ini...
Ensuring folder /home/scm/.ssh...
Ensuring authorized keys...
Ensuring SSH configured...
Ensuring sshd is restarted...
Ensuring hostname is projectsdemo.rickardlindberg.me...
Ensuring folder /opt/projectsdemo/web...
Ensuring folder /opt/projectsdemo/web/artifacts...
Ensuring folder /opt/projectsdemo/web/scm...
Ensuring folder /opt/projectsdemo/events...
Ensuring pem...
Ensuring key...
Setting up tools...
Setting up CI...
Setting up timezone...
Building /opt/projectsdemo/web/index.html...
We now have our Fedora server configured as a code hosting platform! But it looks a little empty at the moment:
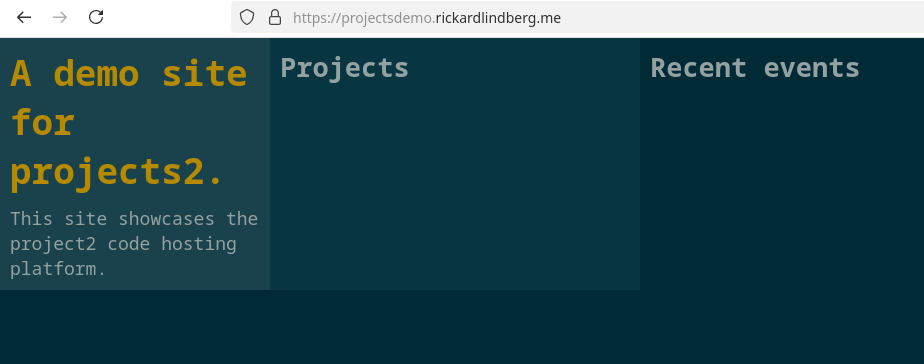
Adding a project
Let’s add a project to our config.ini and also fix two typos that I made in
the title and description:
[Global]
...
Title = A demo site for projects2
Description = This site showcases the projects2 code hosting platform.
[Project:demo]
Scm = git
Description = A demo project.
To apply these changes, we run the update command:
$ path/to/projects2.py update
Ensuring myself...
Ensuring myself api...
Ensuring config.ini...
Ensuring folder /home/scm/.ssh...
Ensuring authorized keys...
Ensuring SSH configured...
Ensuring hostname is projectsdemo.rickardlindberg.me...
Ensuring folder /opt/projectsdemo/web...
Ensuring folder /opt/projectsdemo/web/artifacts...
Ensuring folder /opt/projectsdemo/web/scm...
Ensuring folder /opt/projectsdemo/events...
Ensuring pem...
Ensuring key...
Setting up tools...
Setting up CI...
Setting up timezone...
Configuring project demo...
Ensuring pre-receive hook...
Ensuring post-update hook...
Building /opt/projectsdemo/web/demo.html...
Building /opt/projectsdemo/web/index.html...
And now the demo project appears on the website along with the fixed texts:
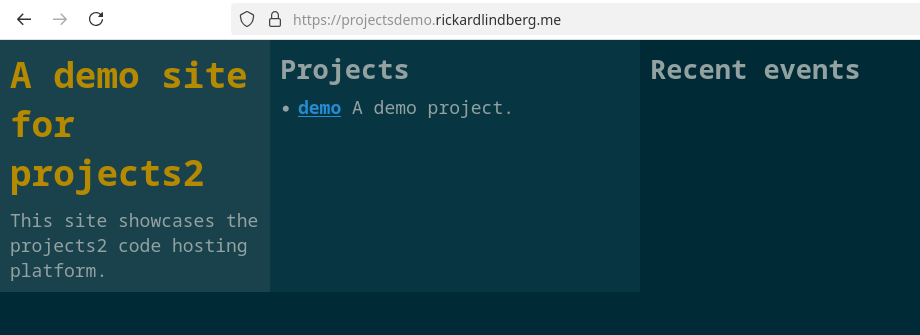
Pushing code to the project
We have an empty git project setup up. Let’s push some code to it:
$ git init demo
$ cd demo
$ git branch -m main
$ vim README.md
$ git add README.md
$ git commit -m 'Add readme.'
$ git remote add origin scm@projectsdemo.rickardlindberg.me:demo.git
$ git push -u origin main
Enumerating objects: 3, done.
Counting objects: 100% (3/3), done.
Writing objects: 100% (3/3), 239 bytes | 239.00 KiB/s, done.
Total 3 (delta 0), reused 0 (delta 0), pack-reused 0 (from 0)
remote: Hello from projects2 pre-receive hook!
remote: Ensuring /opt/projectsdemo/web/demo gone...
remote: Building /opt/projectsdemo/web/index.html...
remote: Building /opt/projectsdemo/web/demo.html...
To projectsdemo.rickardlindberg.me:demo.git
* [new branch] main -> main
branch 'main' set up to track 'origin/main'.
The website updates to show that we pushed some code to the demo project:
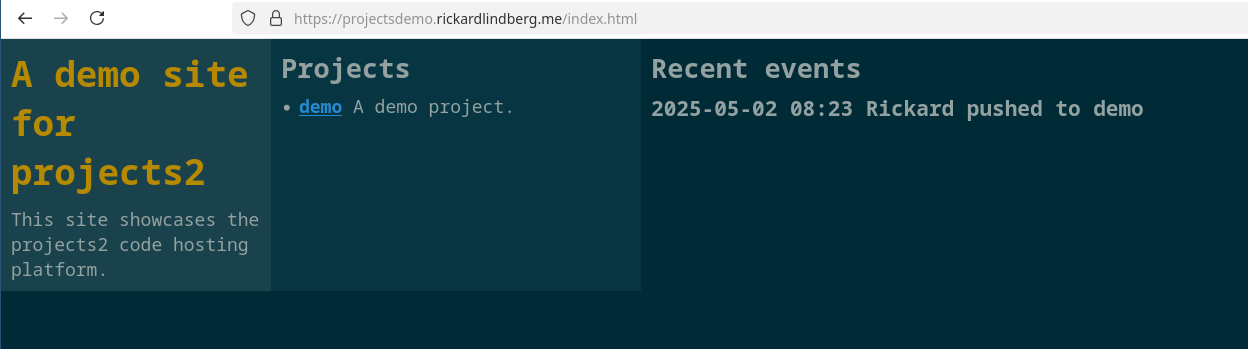
We can make more changes as usual and push them:
$ ...make changes...
$ git push
Enumerating objects: 5, done.
Counting objects: 100% (5/5), done.
Writing objects: 100% (3/3), 281 bytes | 281.00 KiB/s, done.
Total 3 (delta 0), reused 0 (delta 0), pack-reused 0 (from 0)
remote: Hello from projects2 pre-receive hook!
remote: Ensuring /opt/projectsdemo/web/demo gone...
remote: Building /opt/projectsdemo/web/index.html...
remote: Building /opt/projectsdemo/web/demo.html...
To projectsdemo.rickardlindberg.me:demo.git
b81aad4..6f7b10a main -> main
And the diff will appear in the event log:
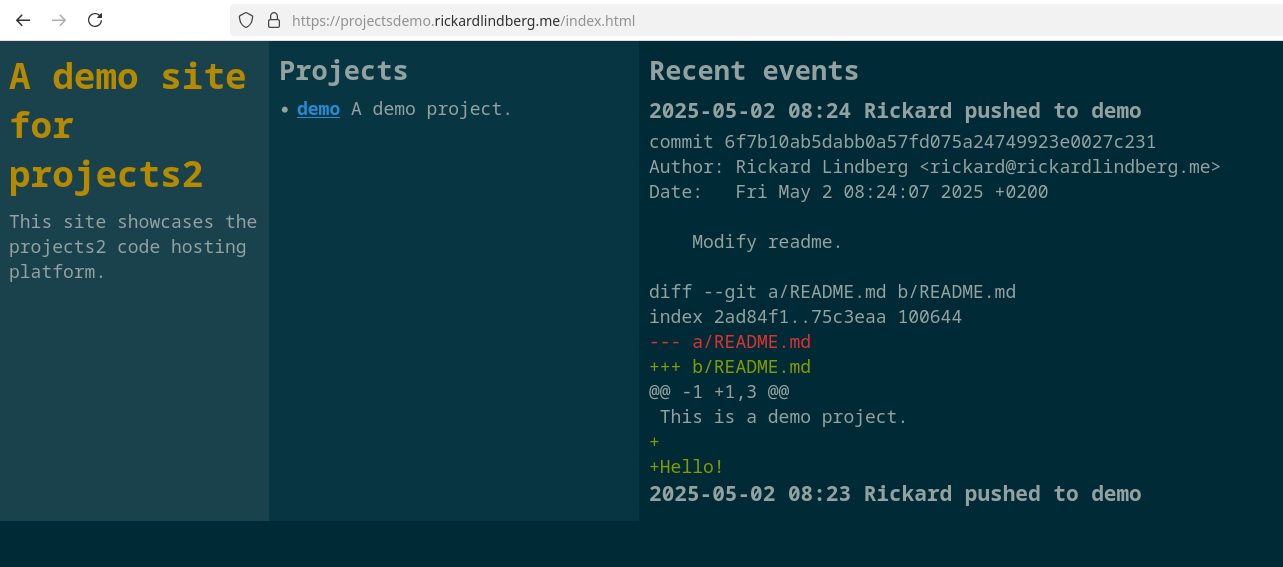
CI
You might have noticed that the push log includes lines like these:
remote: Building /opt/projectsdemo/web/index.html...
remote: Building /opt/projectsdemo/web/demo.html...
When we push code, projects2, intercepts that push to update the website. This mechanism is also used for Continuous Integration (CI).
In our repo, we can add files called Dockerfile*.ci. Those define Docker
images in which the CI scripts are run. Let’s add Dockerfile.py312.ci to our
demo project:
FROM python:3.12
CMD ["python3.12", "build.py"]
It says that the CI command to run is python3.12 build.py. Here is what
build.py looks like:
#!/usr/bin/env python3
import json
import os
import sys
binary_path = "binary"
site_root = "html"
with open(binary_path, "w") as f:
f.write("the compiled binary")
os.makedirs(site_root)
with open(os.path.join(site_root, "index.html"), "w") as f:
f.write("hello from demo site")
with open("Dockerfile.py312.ci.files", "w") as f:
f.write(json.dumps({
"artifacts": [
{
"source": binary_path,
"destination": "binary",
},
],
"site": site_root,
}))
It simulates building a binary which looks like this:
$ cat binary
the compiled binary
And it builds a project website that looks like this:
$ cat html/index.html
hello from demo site
It tells projects2 about these artifacts via the file
Dockerfile.py312.ci.files that looks like this:
{
"artifacts": [
{
"source": "binary",
"destination": "binary"
}
],
"site": "html"
}
When we push this change, we can see the following addition in the log:
remote: Building Dockerfile.py312.ci...
remote: Running Dockerfile.py312.ci...
The Dockerfile.py312.ci.files is parsed by projects2 and the binary file
has been saved as an artifact along with the project website. The link to the
binary is shown in the event log:
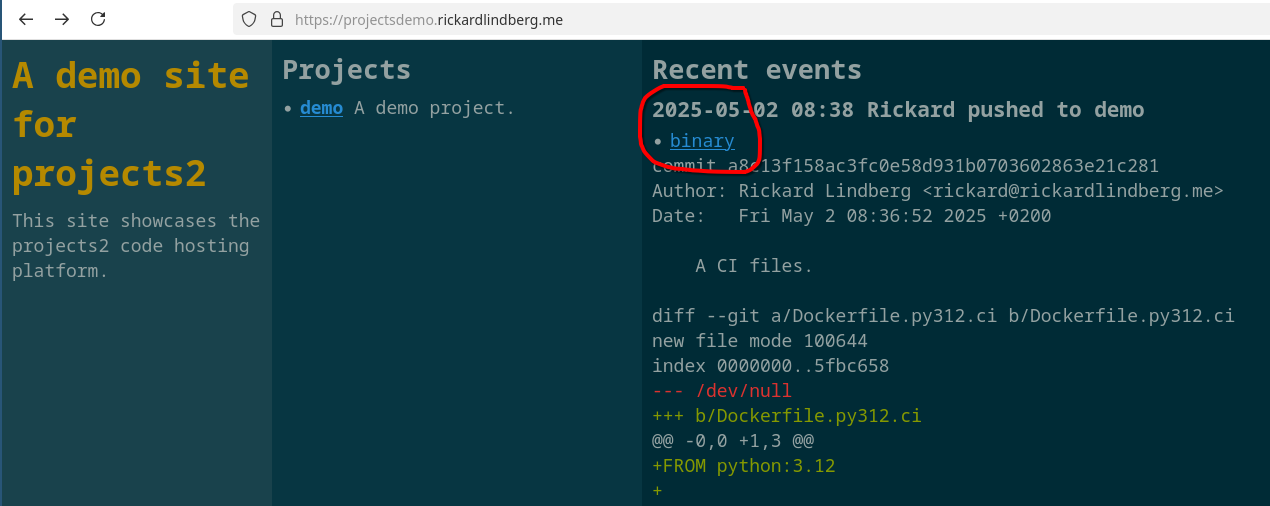
And we can verify that it is correct like this:
$ curl https://projectsdemo.rickardlindberg.me/artifacts/demo/binary
the compiled binary
The project website is also published at <domain>/demo:
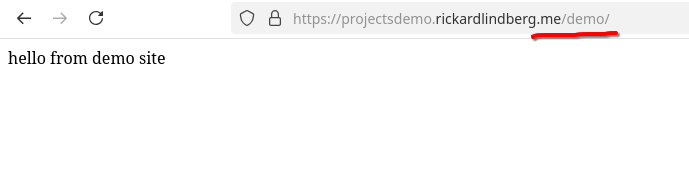
This CI workflow is so nice. In my opinion, it is also much better than Jenkins'. It implements real CI. We just push code as we normally do. If the build brakes, the code will not get pushed and we can try again.
Summary
projects2 is now complete enough that I can start using it for my projects. For Timeline, we can replace all infrastructure from SourceForge and my Jenkins instance with projects2. Almost. We still use the mailing list from SourceForge. And maybe we will continue doing that. I’m not sure that registration free discussions and pull requests are as important to me as I thought. Mostly because there are not many contributors to my projects. But I might incorporate some kind of communication mechanism into projects2.
I couldn’t have implemented projects2 say 5 years ago. I wasn’t as good at Agile development and couldn’t have implemented the simplest thing that could possible work. I have many prior projects to thank for that. In particular I did the simplest thing that could possibly work. Here’s what happened. and Agile Game Development with Python and Pygame. I also couldn’t have come up with this solution for CI without prior reading, thinking, and prototyping solutions. I think the takeaway here is that you need to do many projects. From each project you will learn something that you can incorporate into your next project. Most projects will fail, but you will learn something. And eventually you will have a success. I have a feeling that projects2 might be a success. It is successful now in the sense that I actually use it. Time will tell for how long.
Newsletter March 2025: Snowboarding
This month I have done nothing related to programming in my spare time. Partly because it is snowboard season.

I’m most interested in continuing work on my own code hosting platform that will host my projects. We’ll see if I have the time and motivation next month. Or if something completely different catches my interest.
Replacing Ctrl-R in Bash without TIOCSTI
I have previously written about how I use rlselect as a replacement for Ctrl+R in Bash.
It works by creating a key binding in Bash for Ctrl+R that invokes rlselect
instead of the default Bash interactive history search command. rlselect
looks something like this:
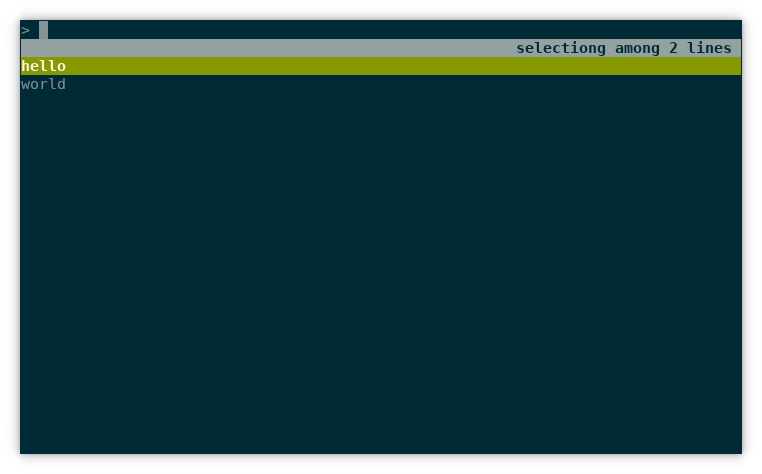
If you press tab, the current selection is inserted at the prompt. If you press enter, the current selection is executed. This is the same behavior as the default Ctrl+R.
The mechanism for this stopped working in recent Linux kernel versions. I figured out how to solve it and in this blog post I explain how.
Old Mechanism
When rlselect is invoked from Ctrl+R, it is invoked with the --tab and
--action flags. The first flag allows the tab key to be used to select a line
and the second makes rlselect print the action taken on the first line
before to the selection.
Here is an example where enter is pressed when “hello” is selected:
$ (echo hello; echo world) | rlselect --tab --action
enter
hello
Here is an example where tab is pressed when “world” is selected:
$ (echo hello; echo world) | rlselect --tab --action
tab
world
Here is an example where Ctrl+G is pressed:
$ (echo hello; echo world) | rlselect --tab --action
ctrl-g
Ctrl+G aborts, so no selection is printed on the second line.
To feed this output to the prompt, TIOCSTI is used. It simulates that you type characters in the terminal. The full script that Ctrl+R invokes looks like this:
set -e
result=$(tac ~/.bash_history | rlselect --tab --action -- "$@")
python - "$result" << EOF
import fcntl
import sys
import termios
action, selection = sys.argv[1].split("\n", 1)
if action != "tab":
selection += "\n"
for ch in selection:
fcntl.ioctl(sys.stdout.fileno(), termios.TIOCSTI, ch)
EOF
The last part is where TIOCSTI is used to simulate that you press the keys of the selection. Unless tab is pressed, it appends a newline to the selection to simulate that Enter is pressed.
The Bash configuration looks like this:
if [[ $- =~ .*i.* ]]; then bind '"\C-r": "\C-a rlselect-history \C-j"'; fi
Here is how it works:
- Ctrl+R is bound to a series of keystrokes.
- First Ctrl+A is simulated which takes the cursor to the beginning of the line.
- Then
<space>rlselect-history<space>is typed. - Then Ctrl+J is simulated which means accept the current line. Or execute it.
The initial space entered in the previous step ensures that the
rlselect-historycommand does not end up in the history. The moving of the cursor to the beginning of the line ensures that anything typed at the prompt is passed as an argument torlselect-history.
(This configuration also makes the text rlselect-history ... appear in the
terminal. The new mechanism makes that go away.)
This mechanism stopped working in recent Linux kernel versions because TIOCSTI can not be used like this. There is apparently security issues with TIOCSTI and it is now only allowed as root.
New Mechanism
The new Bash configuration for Ctrl+R behavior that I came up with looks like this:
rlselect-history() {
local action
local selection
{
read action
read selection
} < <(tac ~/.bash_history | rlselect --tab --action -- "${READLINE_LINE}")
if [ "$action" = "tab" ]; then
READLINE_LINE="${selection}"
READLINE_POINT=${#READLINE_LINE}
bind '"\C-x2":' # Bind Ctrl+x+2 to do nothing
elif [ "$action" = "enter" ]; then
READLINE_LINE="${selection}"
READLINE_POINT=${#READLINE_LINE}
bind '"\C-x2": accept-line' # Bind Ctrl+x+2 to accept line
else
bind '"\C-x2":' # Bind Ctrl+x+2 to do nothing
fi
}
if [[ $- =~ .*i.* ]]; then
# Bind history command to Ctrl+x+1 followed by Ctrl+x+2:
bind '"\C-r": "\C-x1\C-x2"'
# Bind Ctrl+x+1 to execute rlselect-history which does two things:
# 1. Sets READLINE_*
# 2. Binds Ctrl+x+2 to either accept line or do nothing.
bind -x '"\C-x1": rlselect-history'
fi
Let’s break this down.
-
Ctrl+R is bound to a series of keystrokes.
-
First Ctrl+X+1 is simulated.
-
Then Ctrl+X+2 is simulated.
-
Ctrl+X+1 is bound to execute the command
rlselect-history. The-xto bind ensures that the variablesREADLINE_*can be set. Fromman bashonset -x:Cause shell-command to be executed whenever keyseq is entered. When shell-command is executed, the shell sets the READLINE_LINE variable to the contents of the readline line buffer and the READLINE_POINT and READLINE_MARK variables […] If the executed command changes the value of any of READLINE_LINE, READLINE_POINT, or READLINE_MARK, those new values will be reflected in the editing state.
-
rlselect-historyis defined as a Bash function which allows it to reconfigure the key binding for Ctrl+X+2. Depending on if the current selection should be executed or not, it binds Ctrl+X+2 to eitheraccept-lineor nothing.
So the new mechanism relies on using two extra key bindings: Ctrl+X+1 and Ctrl+X+2. I chose them because I don’t use them otherwise. But they can be any two key bindings.
The trick to finding this solution for me was understanding Bash key bindings. This answer on StackOverflow writes the following:
With
bind, you can bind keys to do one of three things, but no combination of them:
- Execute a readline command:
bind '"key": command'- Execute a series of keystrokes:
bind '"key":"keystrokes"'- Execute a shell command:
bind -x '"key": shell-command'
That made me understand that you can not call accept-line from within
rlselect-history because it is executed in the context of bind -x, and
readline commands can only be executed in the context of bind '"key":
command'.
Resources
Here are some resources that talks about the problem with TIOCSTI that helped me:
-
hstr (the program that initially inspired me to write
rlselect) had a similar problem and I found clues to my solution there. -
The fzf-plugins repo and this dicussion provides a similar solution for fzf.
-
The article Readline and Fuzzy Finder helped me understand how to work with
READLINE_*in Bash.
Today’s realization is that you can get important things done by consistently working on them for 15 minutes at the start of every day.
By doing it at the start of the day, you ensure that it gets done. And the rest of the day you don’t need to be stressed about not working on your important thing, because you already have.
Newsletter December 2024: Advent of Code
December is the month of Advent of Code. I had told myself not to participate this year because I know I get completely consumed by the problems and it has a negative impact on the rest of my life. It worked. Until December 15th. More on that later.
Code Editor Update
Last month I started working on a new code editor. It is a mix of a text editor and a structured editor. It is all text, but parsers and pretty printers allow you to work with a tree structure and not think too much about syntax.
I continued working on it this month. The big achievement was that I added support for another language in addition to JSON. The other language is rlmeta. Here is a screenshot showing the parser opened in the editor:
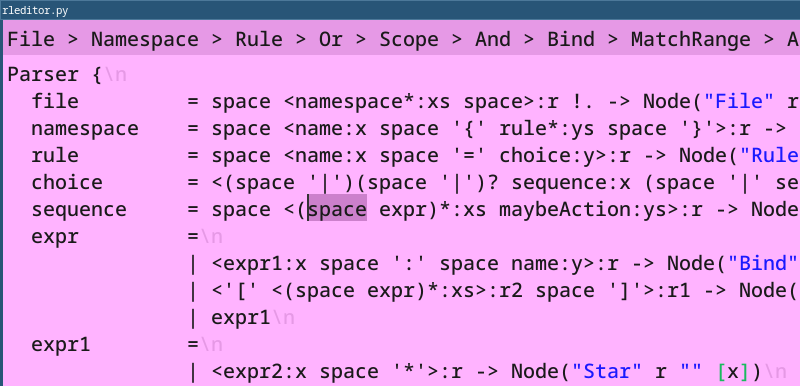
This is a big achievement because it ties everything together. You define a parser and a pretty printer for your language. That gives you all editing capabilities. However, you can also write a code generator, and now you have a full blown programming language with editing support “for free”. This potentially provides an environment to quickly experiment with new programming languages.
Conceptually, I’m quite happy with this achievement. However, there are many things to work on before this is “production ready”. First of all, the performance is pretty horrible because of the constant parsing and pretty printing. Second of all, I need to see if a tree based editor can actually become better than a regular text editor.
Advent of Code
I couldn’t help myself but to participate this year as well. The experience was not as stressful as last year. I still got consumed by the problems, but the feeling was mostly positive. I managed to complete all but 3 problems. Right now, the interest to complete them is pretty low. I might take a look at other solutions to see if I can learn something from that.
My approach to solving the problems is that I try to solve them in order, and I don’t look at others' solutions until I have solved both parts. However, I’m out of ideas to try on the last problems, and I think the competition part is over by now. I might learn something for next year if I look at solutions now.
This year I also practiced object oriented design. So my solutions involve many small objects interacting with each other to produce a solution. It was mostly a success I think. One of my favorite solutions is for day 11.
This year I also think that I got the hang of Dijkstra and A*. (I found Introduction to the A* Algorithm from Red Blob Games really helpful.)
You can find all my solutions on GitHub.
Newsletter November 2024: A New Project
Compared to last month, this month I did some programming in my spare time. I had fewer commitments, and my mind started thinking about various programming projects. We also got the first snowfall of the season and I got to enjoy a run in it:

A New Code Editor
The programming project that I started working on is code editor that is a mix of a text editor and a structured editor. It is all text, but parsers and pretty printers allow you to work with a tree structure and not think too much about syntax. The code is available on GitHub, and here is what it looks like when editing a JSON document:

I got the idea for this project when trying out Black. Black automatically formats Python code for you so that you don’t have to think about it. I’ve been interested in structured editors for some time, but my feeling is that they are not user friendly because they limit what you can type. Then I came up with this idea of an editor that constantly parses what you type. If the parse is successful, it pretty prints it for you and provides you with edit operations on the AST. But it is all still just text, so you can type whatever. In the worst case, the parse fails and you have to fix it manually.
So far, it looks quite promising. And most importantly, I’m having fun experimenting. The most likely scenario is that the project will not be a success, but I will learn something and have fun doing so. But you never know. One day, one of these projects just might turn into something that is invaluable.
TDD
This month I also watched a presentation by Kent Beck called TDD: Theme & Variations. For me, it was a nice refresher on the origins of TDD.
One thing that I appreciate with TDD, that I partially had forgotten, is how it reduces anxiety. Kent reminded me of it in the presentation. When all tests are passing and you can’t think of any more tests to write, you are done, and you know that it works. That reduces anxiety a lot.
Today I ran part of the way to work. It was a cold, beautiful winter morning in Stockholm.

Sometimes, I solve programming problems by coding on paper. A few days ago, it looked like this:

I’ve started working on a code editor that is a mix of a text editor and a structured editor. It is all text, but parsers and pretty printers allow you to work with a tree structure and not think too much about syntax. It is a work in progress. Code is here.
We got some more snow. I like running in the winter. Especially when there is snow and the sun is shining.
I needed to submit some heic photos to a service that only accepted jpg. I didn’t know about the heic format, but a little searching gave me a solution:
$ heif-convert
bash: heif-convert: command not found...
Install package 'libheif' to provide command 'heif-convert'? [N/y] y
...
$ find . -iname '*.heic' -exec heif-convert -q 100 {} {}.jpg \;
Today was the first day of snow this season. Not much. I’m looking forward to many more runs on a white trail.

I was researching how to run Black (and possibly other formatters) from Vim and found Ergonomic mappings for code formatting in Vim. It was very helpful.
How would you improve this code?
def update_r_users(service)
r_users = []
for user in service.get_all_users():
if "r" in user:
r_users.append(user)
service.set_users_in_group("users_with_r_in_name", r_users)
Find out what I did it in my latest newsletter.
Today I learned about the Rison data serialization format. I wrote a function to convert a Python value to Rison format. It was an elegant recursive function with partial support for the format.
I’ve used testing without mocks quite extensively now. I’ve also used it in a work project for more than a year. My experience is that it’s the best testing strategy that I’ve ever used. I’ve never felt more confident that my code works. I refactor code without fear of it breaking. It’s so good.
It’s getting dark. It gives variation to the running.
