
Bash
- Ctrl+R is bound to a series of keystrokes.
- First Ctrl+A is simulated which takes the cursor to the beginning of the line.
- Then
<space>rlselect-history<space>is typed. - Then Ctrl+J is simulated which means accept the current line. Or execute it.
The initial space entered in the previous step ensures that the
rlselect-historycommand does not end up in the history. The moving of the cursor to the beginning of the line ensures that anything typed at the prompt is passed as an argument torlselect-history. -
Ctrl+R is bound to a series of keystrokes.
-
First Ctrl+X+1 is simulated.
-
Then Ctrl+X+2 is simulated.
-
Ctrl+X+1 is bound to execute the command
rlselect-history. The-xto bind ensures that the variablesREADLINE_*can be set. Fromman bashonset -x:Cause shell-command to be executed whenever keyseq is entered. When shell-command is executed, the shell sets the READLINE_LINE variable to the contents of the readline line buffer and the READLINE_POINT and READLINE_MARK variables […] If the executed command changes the value of any of READLINE_LINE, READLINE_POINT, or READLINE_MARK, those new values will be reflected in the editing state.
-
rlselect-historyis defined as a Bash function which allows it to reconfigure the key binding for Ctrl+X+2. Depending on if the current selection should be executed or not, it binds Ctrl+X+2 to eitheraccept-lineor nothing. - Execute a readline command:
bind '"key": command' - Execute a series of keystrokes:
bind '"key":"keystrokes"' - Execute a shell command:
bind -x '"key": shell-command' -
hstr (the program that initially inspired me to write
rlselect) had a similar problem and I found clues to my solution there. -
The fzf-plugins repo and this dicussion provides a similar solution for fzf.
-
The article Readline and Fuzzy Finder helped me understand how to work with
READLINE_*in Bash. - stdin (0)
- stdout (1)
- stderr (2)
- stdin: terminal/keyboard
- stdout: terminal
- stderr: terminal
<means modify stdin.>means modify stdout.2>means modify stderr.- stdin: terminal/keyboard
- stdout: terminal
- stderr: terminal
- stdin:
logcat.py(opened in read mode) - stdout: terminal
- stderr: terminal
- stdin:
logcat.py(opened in read mode) - stdout:
/dev/null(opened in write mode) - stderr: terminal
- Arguments:
./logcat.py,is,the,best,thing - Redirects:
<logcat.py,>out.txt,2>&1 - stdin: terminal/keyboard
- stdout: terminal
- stderr: terminal
- stdin:
logcat.py(opened in read mode) - stdout: terminal
- stderr: terminal
- stdin:
logcat.py(opened in read mode) - stdout:
out.txt(opened in write mode) - stderr: terminal
- stdin:
logcat.py(opened in read mode) - stdout:
out.txt(opened in write mode) - stderr:
out.txt(opened in write mode) tac ~/.bash_historyecho frustrationecho withecho bash
Replacing Ctrl-R in Bash without TIOCSTI
I have previously written about how I use rlselect as a replacement for Ctrl+R in Bash.
It works by creating a key binding in Bash for Ctrl+R that invokes rlselect
instead of the default Bash interactive history search command. rlselect
looks something like this:
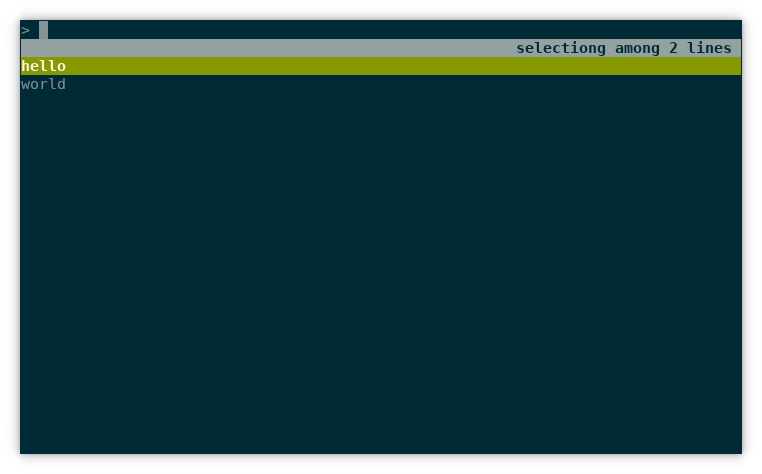
If you press tab, the current selection is inserted at the prompt. If you press enter, the current selection is executed. This is the same behavior as the default Ctrl+R.
The mechanism for this stopped working in recent Linux kernel versions. I figured out how to solve it and in this blog post I explain how.
Old Mechanism
When rlselect is invoked from Ctrl+R, it is invoked with the --tab and
--action flags. The first flag allows the tab key to be used to select a line
and the second makes rlselect print the action taken on the first line
before to the selection.
Here is an example where enter is pressed when “hello” is selected:
$ (echo hello; echo world) | rlselect --tab --action
enter
hello
Here is an example where tab is pressed when “world” is selected:
$ (echo hello; echo world) | rlselect --tab --action
tab
world
Here is an example where Ctrl+G is pressed:
$ (echo hello; echo world) | rlselect --tab --action
ctrl-g
Ctrl+G aborts, so no selection is printed on the second line.
To feed this output to the prompt, TIOCSTI is used. It simulates that you type characters in the terminal. The full script that Ctrl+R invokes looks like this:
set -e
result=$(tac ~/.bash_history | rlselect --tab --action -- "$@")
python - "$result" << EOF
import fcntl
import sys
import termios
action, selection = sys.argv[1].split("\n", 1)
if action != "tab":
selection += "\n"
for ch in selection:
fcntl.ioctl(sys.stdout.fileno(), termios.TIOCSTI, ch)
EOF
The last part is where TIOCSTI is used to simulate that you press the keys of the selection. Unless tab is pressed, it appends a newline to the selection to simulate that Enter is pressed.
The Bash configuration looks like this:
if [[ $- =~ .*i.* ]]; then bind '"\C-r": "\C-a rlselect-history \C-j"'; fi
Here is how it works:
(This configuration also makes the text rlselect-history ... appear in the
terminal. The new mechanism makes that go away.)
This mechanism stopped working in recent Linux kernel versions because TIOCSTI can not be used like this. There is apparently security issues with TIOCSTI and it is now only allowed as root.
New Mechanism
The new Bash configuration for Ctrl+R behavior that I came up with looks like this:
rlselect-history() {
local action
local selection
{
read action
read selection
} < <(tac ~/.bash_history | rlselect --tab --action -- "${READLINE_LINE}")
if [ "$action" = "tab" ]; then
READLINE_LINE="${selection}"
READLINE_POINT=${#READLINE_LINE}
bind '"\C-x2":' # Bind Ctrl+x+2 to do nothing
elif [ "$action" = "enter" ]; then
READLINE_LINE="${selection}"
READLINE_POINT=${#READLINE_LINE}
bind '"\C-x2": accept-line' # Bind Ctrl+x+2 to accept line
else
bind '"\C-x2":' # Bind Ctrl+x+2 to do nothing
fi
}
if [[ $- =~ .*i.* ]]; then
# Bind history command to Ctrl+x+1 followed by Ctrl+x+2:
bind '"\C-r": "\C-x1\C-x2"'
# Bind Ctrl+x+1 to execute rlselect-history which does two things:
# 1. Sets READLINE_*
# 2. Binds Ctrl+x+2 to either accept line or do nothing.
bind -x '"\C-x1": rlselect-history'
fi
Let’s break this down.
So the new mechanism relies on using two extra key bindings: Ctrl+X+1 and Ctrl+X+2. I chose them because I don’t use them otherwise. But they can be any two key bindings.
The trick to finding this solution for me was understanding Bash key bindings. This answer on StackOverflow writes the following:
With
bind, you can bind keys to do one of three things, but no combination of them:
That made me understand that you can not call accept-line from within
rlselect-history because it is executed in the context of bind -x, and
readline commands can only be executed in the context of bind '"key":
command'.
Resources
Here are some resources that talks about the problem with TIOCSTI that helped me:
Bash Redirects Explained
I thought I knew how Bash redirects worked.
If I wanted to redirect the output of a command to a file, I’d type this:
program > /tmp/log.txt
If I wanted to pipe both stdout and stderr to a text editor for further processing, I’d type this:
program 2>&1 | vim -
I knew that 2>&1 meant redirect stderr to stdout making it appear on stdout
as well.
I knew certain patterns for certain situations. But when I encountered situations where I had not learned a pattern, I was lost. For example, I could not explain the difference between
program 2>&1 >/tmp/log.txt
and
program >/tmp/log.txt 2>&1
And I got scared when I saw something like this:
program < input.txt > output.txt 2>&1
Have you also been there? What did you do?
I would search the Internet for a pattern that matched the use case, or just try different alternatives and notice how they behaved.
I did this until one day when I learned a mental model for how Bash redirects work. Now I no longer need to rely on patterns. I can easily parse any situation and use any combination of redirects for my purposes.
The rest of this article explains this mental model.
The Standard Streams
A process has three standard streams attached to it:
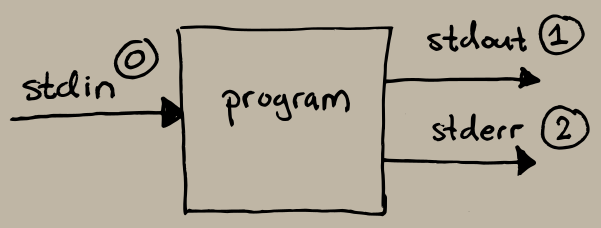
When we start a program from the terminal, Bash sets up the standard streams as follows:
What redirects do is to modify what the standard streams point to before the program starts executing.
That is the mental model: redirects modify standard streams before program execution.
Let’s evaluate a few examples using this mental model to see how it works.
Logcat Utility
To be able to show what happens in different examples, we have a utility
program, logcat.py, that makes use of all three streams. It reads text from
stdin, logs the arguments and the length of the text to stderr, and writes the
text to stdout. It looks like this:
#!/usr/bin/env python
import sys
text = sys.stdin.read()
sys.stderr.write(f"Args: {(sys.argv[1:])}\n")
sys.stderr.write(f"Read {len(text)} characters.\n")
sys.stdout.write(text)
Example: No Redirect
Let’s start with an example without redirects to see the operation of
logcat.py:
$ ./logcat.py ignored arguments
Before logcat.py starts executing, Bash sets up the standard streams as
follows:
When execution starts, logcat.py waits for input. If we type hello in the
terminal (followed by a return and ctrl+d), the following is printed to the
terminal:
Args: ['ignored', 'arguments']
Read 6 characters.
hello
We can see that it read our input from the terminal/keyboard and wrote the log messages along with our input to the terminal as well.
Example: Redirect Stdin
Now let’s modify stdin to instead of the terminal/keyboard be the logcat.py
source code:
$ ./logcat.py ignored arguments <logcat.py
This instructs Bash to modify stdin to point to the file logcat.py.
Before logcat.py starts executing, Bash sets up the standard streams as
follows:
When execution starts, the following is printed to the terminal:
Args: ['ignored', 'arguments']
Read 182 characters.
#!/usr/bin/env python
import sys
text = sys.stdin.read()
sys.stderr.write(f"Args: {(sys.argv[1:])}\n")
sys.stderr.write(f"Read {len(text)} characters.\n")
sys.stdout.write(text)
We can see that the redirect operation is stripped from the arguments. Only
Bash sees it and does not pass it along to the program. Furthermore we can see
that the logcat.py source code is printed to the terminal.
Example: Redirect Stdin and Stdout
Let’s say we’re only interested in the log messages, and want to throw away stdout:
$ ./logcat.py ignored arguments <logcat.py >/dev/null
This instructs Bash to modify stdin to point to the file logcat.py and to
modify stdout to point to the file /dev/null.
Before logcat.py starts executing, Bash sets up the standard streams as
follows:
When execution starts, the following is printed to the terminal:
Args: ['ignored', 'arguments']
Read 182 characters.
We can see that the redirect operations are all stripped from the arguments and
the source code has been written to /dev/null and is thus not shown in the
terminal.
Extended Mental Model
Let’s extended the mental model to clarify how Bash operates.
When Bash parses a command, it divides it into two parts: the arguments and the redirects. Before it starts executing the program with the arguments, it goes through the redirects, in order, and configures the standard streams before execution.
Example: Redirect All Streams
Let’s see how we can interpret a more complex command using the extended mental model:
$ ./logcat.py <logcat.py is the >out.txt best 2>&1 thing
If we split this into arguments and redirects, we get this:
Now, let’s evaluate the redirects in order. The state of the standard streams at start is this:
Then we evaluate <logcat.py and get this:
Then we evaluate >out.txt and get this:
Then we evaluate 2>&1, which means modify stderr (2>) to be whatever
stdout points to (&1), and get this:
After the standard streams have been set up, execution of ./logcat.py is the best thing starts. Nothing appears on the terminal since all output has been
redirected to out.txt:
$ cat out.txt
Args: ['is', 'the', 'best', 'thing']
Read 182 characters.
#!/usr/bin/env python
import sys
text = sys.stdin.read()
sys.stderr.write(f"Args: {(sys.argv[1:])}\n")
sys.stderr.write(f"Read {len(text)} characters.\n")
sys.stdout.write(text)
Mini Shell
I created a mini version of a shell to demonstrate how straight forward it is to implement redirects with POSIX system calls. It works exactly as the extended mental model, and because it is running software, it fills in some more details of the model. I would guess that Bash does something similar even though I haven’t read its source code.
First off, here is a demo that shows how the mini shell can replicate the complex example from above:
$ ./minishell.py
~~?~~> ./logcat.py <logcat.py is the >out.txt best 2>&1 thing
~~0~~> cat out.txt
Args: ['is', 'the', 'best', 'thing']
Read 182 characters.
#!/usr/bin/env python
import sys
text = sys.stdin.read()
sys.stderr.write(f"Args: {(sys.argv[1:])}\n")
sys.stderr.write(f"Read {len(text)} characters.\n")
sys.stdout.write(text)
And here is the implementation in only 31 lines of Python:
#!/usr/bin/env python
import os
import sys
STDIN = 0
STDOUT = 1
STDERR = 2
statuscode = "?"
while True:
sys.stdout.write(f"~~{statuscode}~~> ")
sys.stdout.flush()
command = input()
pid = os.fork()
if pid == 0:
args = []
for part in command.split(" "):
if part.startswith("<"):
os.dup2(os.open(part[1:], os.O_RDONLY), STDIN)
elif part.startswith(">"):
os.dup2(os.open(part[1:], os.O_WRONLY|os.O_CREAT, 0o644), STDOUT)
elif part == "2>&1":
os.dup2(STDOUT, STDERR)
elif part.startswith("2>"):
os.dup2(os.open(part[2:], os.O_WRONLY|os.O_CREAT, 0o644), STDERR)
else:
args.append(part)
os.execvp(args[0], args)
else:
_, statuscode = os.waitpid(pid, 0)
To understand how this works, you need some knowledge of the POSIX system calls
fork, waitpid, open, dup2, and execvp. But even if you don’t
understand the specifics, I think this codified model can help in understanding
how Bash operates. Let’s look at an example.
Example: Duplicated Files
Let’s see if we can explain the difference between the following commands using the mini shell for the model:
$ ./logcat.py <logcat.py >out.txt 2>out.txt
$ ./logcat.py <logcat.py >out.txt 2>&1
At a first glance, it looks like both commands redirect both stdout and stderr
to the out.txt file. But if we evaluate it like mini shell does, we see that
the first example will open the file twice (two calls to os.open creating two
file handles), whereas the second example will open the file only once and then
duplicate the file handle for stderr.
When two file handles are created, writes to the two streams will attempt to write to the same location in the file and they will overwrite each other. Furthermore, buffering might alter in which order writes happen, so it is not clear what will actually end up in the file. So to make sure all output is captured in the file, the second example should be used where the file is only opened once.
Conclusion
There is still more to Bash redirects than what I have explained here. But this mental model (along with its extended versions) have helped me reason about Bash redirects. I hope it will do the same for you.
Evolution of recalling Bash history
This article is about how I’ve become more efficient at using Bash, the interactive UNIX shell.
When I work in Bash, I often want to execute a command again. In the beginning I re-typed the command and pressed enter. This worked fine for short commands, but became tedious for longer commands.
In some shells this is the only way to enter a new command. But Bash remembers the recently executed commands and provides ways to recall them.
Cycle with arrow keys
The first way I learned to recall history was with the arrow keys. If I pressed Up the previous command was inserted at the prompt. I could continue for as long as I wanted. If I pressed Down the next command was inserted at the prompt:
$ ls<Enter>
bin ...
$ date<Enter>
Wed May 10 08:14:46 CEST 2017
$ <Up>
$ date<Up>
$ ls<Down>
$ date<Enter>
Wed May 10 08:14:59 CEST 2017
This worked fine for commands that I had executed recently, but tedious for commands that I had executed long ago because I had to press Up many times. I ended up pressing and holding Up so that history scrolled by and when I saw my command, I released the key and pressed Down until it appeared again.
Cycle with Ctrl-P/Ctrl-N
Later I learned that Ctrl-P (previous) had the same function as Up and that Ctrl-N (next) had the same function as Down.
These shortcuts were more comfortable for me because I like to keep my fingers as close to the home row as possible.
Searching with Ctrl-R
Then I learned about Bash’s interactive history search command. If I pressed Ctrl-R the prompt changed to this:
(reverse-i-search)`':
This special prompt allowed me to type parts of a command that I had executed previously. Say I wanted to execute the last find command again. I typed “find” and the prompt changed to this:
(reverse-i-search)`find': find -name '*.py' -a -type f
The text I typed, “find”, was present before the colon. After the colon the last command that I had executed that contained the string “find” was displayed. In this case I did a search for Python files. If this was not the match I was looking for, I could hit Ctrl-R again and the part to the right of the colon would change to the next command in the history that contained the string “find”. Once I found the command I was looking for I had two options: I could hit Tab to insert the command at the prompt:
$ find -name '*.py' -a -type f
This way I could edit the command before I executed it. Or I could hit Enter to execute the command directly.
Now I was able to recall commands that I had executed long ago. I almost replaced all my usages of Ctrl-P/Ctrl-N with Ctrl-R. Except for the cases where I knew that the command I wanted to recall was only a few entries back.
Frustrations with Ctrl-R
The interactive search worked great for me when I knew what I was looking for. It did not work so great when I was more uncertain or when I mistyped the name of a command.
The interactive search works by having a pointer to en entry in the history. When I typed a command it would move that pointer to the next item in the history that matched. But if I mistyped, the search might still match something further back in history. But when I erased a few characters to correct my mistake, the search would continue from there. Say this was my history:
I hit Ctrl-R to to begin searching for “bash”:
(reverse-i-search)`':
But I mistyped. Instead of “b” I typed “f”:
(reverse-i-search)`f': echo frustration
The search matched item 2. I erased the incorrectly typed character:
(reverse-i-search)`': echo frustration
The match remained. I typed bash correctly:
(reverse-i-search)`bash': tac ~/.bash_history
It now matched item 1 instead of item 4. The search continued from the previous
match. I would have wanted the search to always show the most recent match from
history. The easiest way I found to reset the search after a failure to find
what I was looking for was to just execute a dummy command. Usually I selected
ls because it was short to type and had no side effects.
Interactively filtering with external program
Then I was introduced to hstr by a colleague. It worked like a replacement for Ctrl-R. When I invoked it, it dropped into a text UI where my last history entries were shown. I could also type part of a command to narrow down the list. If I changed the search string, the narrowed down list changed accordingly. When I found a match I could similarly press Tab to insert the command at the prompt or press Enter to execute it immediately. It looked like this:
This solved my frustrations with Bash’s interactive search. For me, this was a far easier way to find items from my history. The fact that it showed the last commands also helped me. I could visually inspect them, and they would guide my search.
hstr was so good that I wanted to use a similar selection mechanism for other
things, but hstr was only for Bash history. I ended up writing my own selection
program: rlselect. Partly because I wanted
such a program, but also because it seemed like a fun program to write. The
core selection program is called rlselect and then there are multiple
programs that use it to allow selecting specific things. rlselect-history is
a replacement for Ctrl-R/hstr:

There are some differences between hstr and rlselect-history. I took only the
parts I personally wanted from hstr and put them into rlselect-history.
If you want to improve your Bash usage, I suggest taking a look at hstr or rlselect.