
newsletter
- A machine running Fedora Linux that we have root access to
- A domain that resolves to that machine
- An SSL certificate for that domain
-
I configured different note types to show in different colors. Zettelkasten has a few different kinds of notes, and quickly being able to see, by color, which it is, has been helpful.
-
I added the ability to change the order of notes. This was needed to be able to create structure notes with links in specific order.
-
I added the ability to give links a text description. This is what allowed me to experiment with articulating how two ideas relate to each other. I wrote more about the evolution of this feature in Linking (and how it has evolved) in Smart Notes.
-
I documented how I did a redirect to my old archived site for pages that I have not yet migrated to the new blog in Poor man’s redirect in a static site.
-
I started a “photo blog” documenting my runs and how my life improves from them.
-
Micro.blog makes it easy to create a website that feels like a home.
I can share and develop my interests. I can structure content with categories and pages. Others can come have a look. Comment if they wish. And you can see conversations that I’ve had with visitors.
-
It makes blogging fun. It is easy to publish and you can get comments from the community on your posts.
Newsletter April 2025: projects2
This month I’ve done a lot of programming. I ended up working more on my own code hosting platform. I call it projects2. Why two? Because it’s my second attempt at implementing this idea. Second attempt in recent times at least.
In my 2017 blog post, A new home for Timeline, I wrote
My suggested way forward is therefore to develop a new platform whose core features are registration free discussions and pull requests. In addition, it would need features common to many platforms like hosting of releases and a project web page.
In my previous attempt I focused on registration free discussions. This time, I decided to instead focus on creating the minimal possible software that allowed us to move away from SourceForge for Timeline and also get rid of the Jenkins instance that I run. That way, the infrastructure for running Timeline would not depend on proprietary systems or “complicated” third party software (Jenkins) which is overkill for our needs.
What follows is a demo of the current state of projects2.
Requirements
To use projects2 we need the following:
I use DNSimple to purchase domains and SSL certificates and Linode to provision Fedora servers.
Initial setup
projects2 is implemented as a single Python script, projects2.py, which is
used to configure a single Fedora Linux machine to act as a code hosting
platform.
We configure our server in a config.ini file. Let’s use this for the demo:
[Global]
InstanceName = projectsdemo
Domain = projectsdemo.rickardlindberg.me
Title = A demo site for projects2.
Description = This site showcases the project2 code hosting platform.
[User:admin]
DisplayName = Rickard
SshKeys = <my public ssh key>
Projects = *
[WildcardCertificate]
pem = <my ssl certificate>
key = <my ssl private key>
Next we run the bootstrap command, which should only be run once on a fresh
Fedora install:
$ path/to/projects2.py bootstrap
ssh root login prompt
...
Ensuring user scm...
Ensuring passwordless sudo for scm...
Ensuring folder /home/scm/.ssh...
Ensuring authorized keys...
Ensuring folder /opt/projectsdemo...
Ensuring folder /opt/projectsdemo/web/artifacts...
Ensuring myself...
Ensuring myself api...
Ensuring config.ini...
Ensuring folder /home/scm/.ssh...
Ensuring authorized keys...
Ensuring SSH configured...
Ensuring sshd is restarted...
Ensuring hostname is projectsdemo.rickardlindberg.me...
Ensuring folder /opt/projectsdemo/web...
Ensuring folder /opt/projectsdemo/web/artifacts...
Ensuring folder /opt/projectsdemo/web/scm...
Ensuring folder /opt/projectsdemo/events...
Ensuring pem...
Ensuring key...
Setting up tools...
Setting up CI...
Setting up timezone...
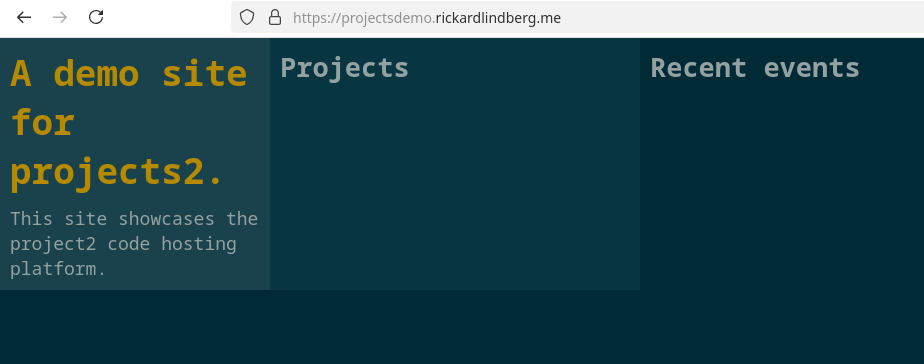
Building /opt/projectsdemo/web/index.html...
We now have our Fedora server configured as a code hosting platform! But it looks a little empty at the moment:
Adding a project
Let’s add a project to our config.ini and also fix two typos that I made in
the title and description:
[Global]
...
Title = A demo site for projects2
Description = This site showcases the projects2 code hosting platform.
[Project:demo]
Scm = git
Description = A demo project.
To apply these changes, we run the update command:
$ path/to/projects2.py update
Ensuring myself...
Ensuring myself api...
Ensuring config.ini...
Ensuring folder /home/scm/.ssh...
Ensuring authorized keys...
Ensuring SSH configured...
Ensuring hostname is projectsdemo.rickardlindberg.me...
Ensuring folder /opt/projectsdemo/web...
Ensuring folder /opt/projectsdemo/web/artifacts...
Ensuring folder /opt/projectsdemo/web/scm...
Ensuring folder /opt/projectsdemo/events...
Ensuring pem...
Ensuring key...
Setting up tools...
Setting up CI...
Setting up timezone...
Configuring project demo...
Ensuring pre-receive hook...
Ensuring post-update hook...
Building /opt/projectsdemo/web/demo.html...
Building /opt/projectsdemo/web/index.html...
And now the demo project appears on the website along with the fixed texts:
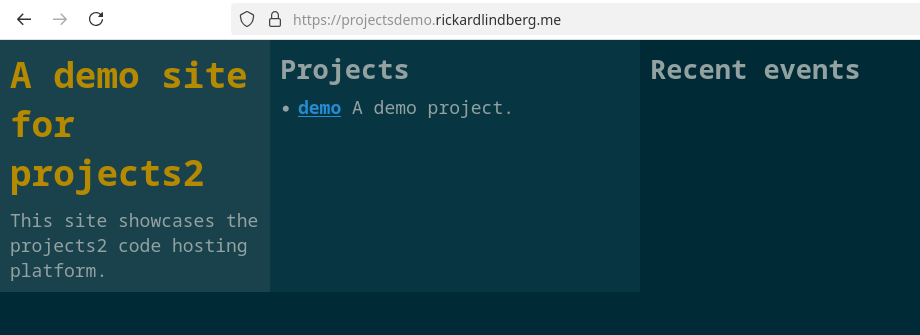
Pushing code to the project
We have an empty git project setup up. Let’s push some code to it:
$ git init demo
$ cd demo
$ git branch -m main
$ vim README.md
$ git add README.md
$ git commit -m 'Add readme.'
$ git remote add origin scm@projectsdemo.rickardlindberg.me:demo.git
$ git push -u origin main
Enumerating objects: 3, done.
Counting objects: 100% (3/3), done.
Writing objects: 100% (3/3), 239 bytes | 239.00 KiB/s, done.
Total 3 (delta 0), reused 0 (delta 0), pack-reused 0 (from 0)
remote: Hello from projects2 pre-receive hook!
remote: Ensuring /opt/projectsdemo/web/demo gone...
remote: Building /opt/projectsdemo/web/index.html...
remote: Building /opt/projectsdemo/web/demo.html...
To projectsdemo.rickardlindberg.me:demo.git
* [new branch] main -> main
branch 'main' set up to track 'origin/main'.
The website updates to show that we pushed some code to the demo project:
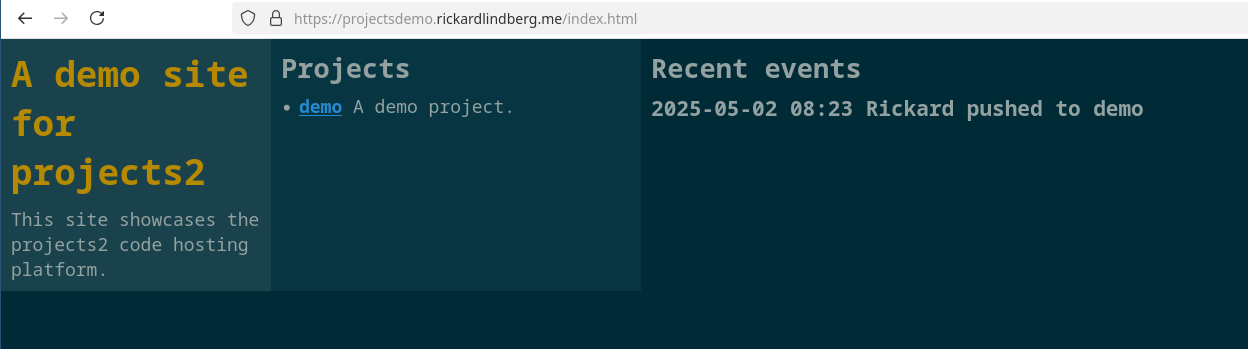
We can make more changes as usual and push them:
$ ...make changes...
$ git push
Enumerating objects: 5, done.
Counting objects: 100% (5/5), done.
Writing objects: 100% (3/3), 281 bytes | 281.00 KiB/s, done.
Total 3 (delta 0), reused 0 (delta 0), pack-reused 0 (from 0)
remote: Hello from projects2 pre-receive hook!
remote: Ensuring /opt/projectsdemo/web/demo gone...
remote: Building /opt/projectsdemo/web/index.html...
remote: Building /opt/projectsdemo/web/demo.html...
To projectsdemo.rickardlindberg.me:demo.git
b81aad4..6f7b10a main -> main
And the diff will appear in the event log:
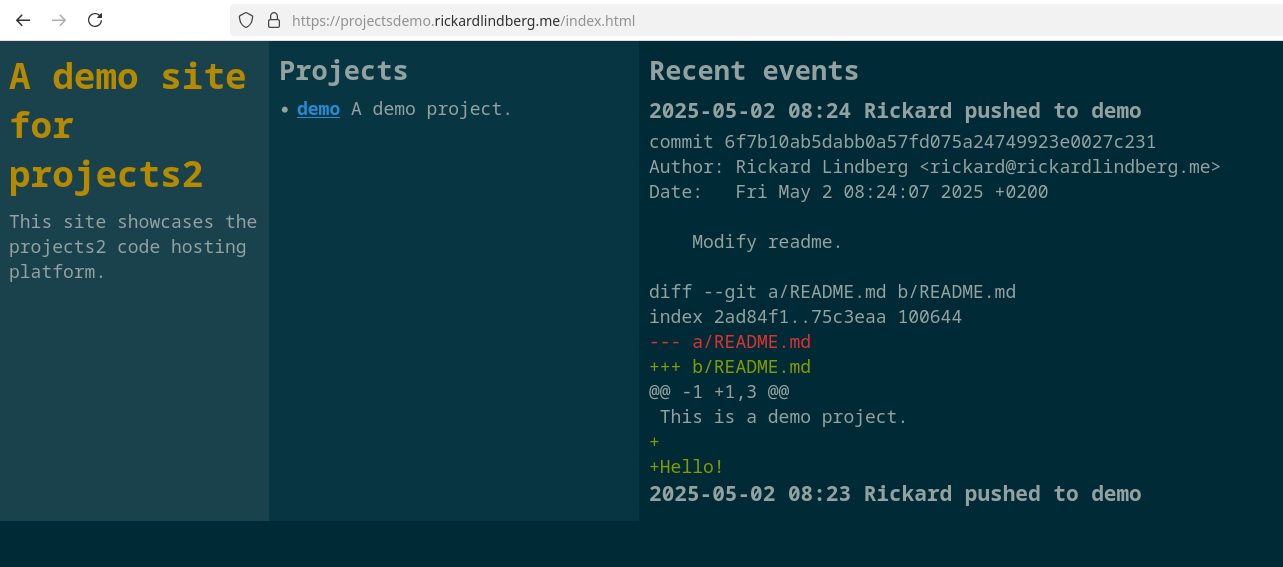
CI
You might have noticed that the push log includes lines like these:
remote: Building /opt/projectsdemo/web/index.html...
remote: Building /opt/projectsdemo/web/demo.html...
When we push code, projects2, intercepts that push to update the website. This mechanism is also used for Continuous Integration (CI).
In our repo, we can add files called Dockerfile*.ci. Those define Docker
images in which the CI scripts are run. Let’s add Dockerfile.py312.ci to our
demo project:
FROM python:3.12
CMD ["python3.12", "build.py"]
It says that the CI command to run is python3.12 build.py. Here is what
build.py looks like:
#!/usr/bin/env python3
import json
import os
import sys
binary_path = "binary"
site_root = "html"
with open(binary_path, "w") as f:
f.write("the compiled binary")
os.makedirs(site_root)
with open(os.path.join(site_root, "index.html"), "w") as f:
f.write("hello from demo site")
with open("Dockerfile.py312.ci.files", "w") as f:
f.write(json.dumps({
"artifacts": [
{
"source": binary_path,
"destination": "binary",
},
],
"site": site_root,
}))
It simulates building a binary which looks like this:
$ cat binary
the compiled binary
And it builds a project website that looks like this:
$ cat html/index.html
hello from demo site
It tells projects2 about these artifacts via the file
Dockerfile.py312.ci.files that looks like this:
{
"artifacts": [
{
"source": "binary",
"destination": "binary"
}
],
"site": "html"
}
When we push this change, we can see the following addition in the log:
remote: Building Dockerfile.py312.ci...
remote: Running Dockerfile.py312.ci...
The Dockerfile.py312.ci.files is parsed by projects2 and the binary file
has been saved as an artifact along with the project website. The link to the
binary is shown in the event log:
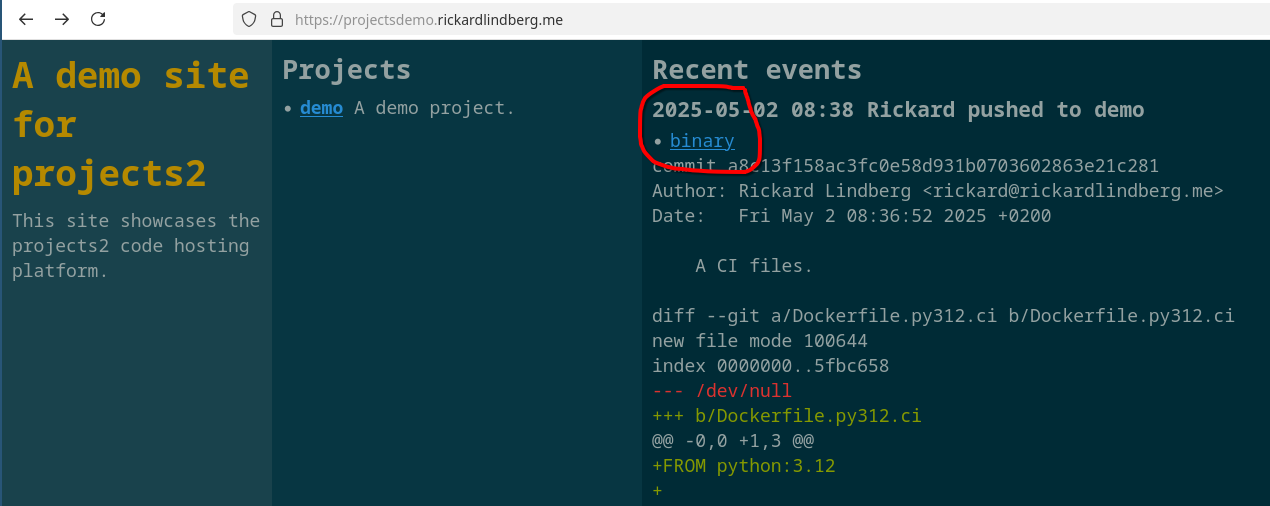
And we can verify that it is correct like this:
$ curl https://projectsdemo.rickardlindberg.me/artifacts/demo/binary
the compiled binary
The project website is also published at <domain>/demo:
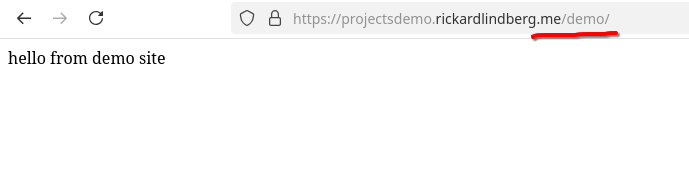
This CI workflow is so nice. In my opinion, it is also much better than Jenkins'. It implements real CI. We just push code as we normally do. If the build brakes, the code will not get pushed and we can try again.
Summary
projects2 is now complete enough that I can start using it for my projects. For Timeline, we can replace all infrastructure from SourceForge and my Jenkins instance with projects2. Almost. We still use the mailing list from SourceForge. And maybe we will continue doing that. I’m not sure that registration free discussions and pull requests are as important to me as I thought. Mostly because there are not many contributors to my projects. But I might incorporate some kind of communication mechanism into projects2.
I couldn’t have implemented projects2 say 5 years ago. I wasn’t as good at Agile development and couldn’t have implemented the simplest thing that could possible work. I have many prior projects to thank for that. In particular I did the simplest thing that could possibly work. Here’s what happened. and Agile Game Development with Python and Pygame. I also couldn’t have come up with this solution for CI without prior reading, thinking, and prototyping solutions. I think the takeaway here is that you need to do many projects. From each project you will learn something that you can incorporate into your next project. Most projects will fail, but you will learn something. And eventually you will have a success. I have a feeling that projects2 might be a success. It is successful now in the sense that I actually use it. Time will tell for how long.
Newsletter March 2025: Snowboarding
This month I have done nothing related to programming in my spare time. Partly because it is snowboard season.

I’m most interested in continuing work on my own code hosting platform that will host my projects. We’ll see if I have the time and motivation next month. Or if something completely different catches my interest.
Newsletter November 2024: A New Project
Compared to last month, this month I did some programming in my spare time. I had fewer commitments, and my mind started thinking about various programming projects. We also got the first snowfall of the season and I got to enjoy a run in it:

A New Code Editor
The programming project that I started working on is code editor that is a mix of a text editor and a structured editor. It is all text, but parsers and pretty printers allow you to work with a tree structure and not think too much about syntax. The code is available on GitHub, and here is what it looks like when editing a JSON document:

I got the idea for this project when trying out Black. Black automatically formats Python code for you so that you don’t have to think about it. I’ve been interested in structured editors for some time, but my feeling is that they are not user friendly because they limit what you can type. Then I came up with this idea of an editor that constantly parses what you type. If the parse is successful, it pretty prints it for you and provides you with edit operations on the AST. But it is all still just text, so you can type whatever. In the worst case, the parse fails and you have to fix it manually.
So far, it looks quite promising. And most importantly, I’m having fun experimenting. The most likely scenario is that the project will not be a success, but I will learn something and have fun doing so. But you never know. One day, one of these projects just might turn into something that is invaluable.
TDD
This month I also watched a presentation by Kent Beck called TDD: Theme & Variations. For me, it was a nice refresher on the origins of TDD.
One thing that I appreciate with TDD, that I partially had forgotten, is how it reduces anxiety. Kent reminded me of it in the presentation. When all tests are passing and you can’t think of any more tests to write, you are done, and you know that it works. That reduces anxiety a lot.
Newsletter August 2024: Smart Notes and Blogging
In August I had my last week of summer vacation. I read a book that made me want to improve my note taking tool, I did some programming on hobby projects, and I migrated my blog to a new platform. All while doing many runs.
A System for Writing
I read A System for Writing by Bob Doto. This review is what made me buy the book:
When I first tried to get my head around Zettelkasten, I consulted Sönke Ahrens’ extremely useful book How to Take Smart Notes. This was—and still is—seen as the book to read on the subject. I predict A System for Writing will replace it.
I liked Sönke’s book, and I was curious to learn more about this topic from a source that seemed credible.
I got some new insights about the Zettelkasten method. In particular the idea that it is important to articulate how two ideas relate. I’ve previously mostly connected ideas without context. The connection was obvious when I made it, but most likely less obvious when I come back to it.
I tried to research this a bit more and found the article Backlinking Is Not Very Useful – Often Even Harmful:
A good link context explains what you can expect if you follow the link. But it can also explain the nature of the relationship between both notes.
I wanted to try this out.
Smart Notes
I use my Smart Notes app to take notes using the Zettelkasten method. When I studied the method more, I got some new ideas that I implemented:
One-File Programs
I continued to work on One-File Programs.
I worked on an engine app that can automatically reload other apps when they change. This gives faster feedback, especially when working on graphical applications. It is similar to an approach I’ve written about previously in How to get fast feedback on graphical code?
I also worked on the no scrollbars app. I wanted to see if we can get rid of scrollbars in some GUI elements. The idea is to make items larger around the area of the mouse so that they can more easily get selected. Here is one screenshot:
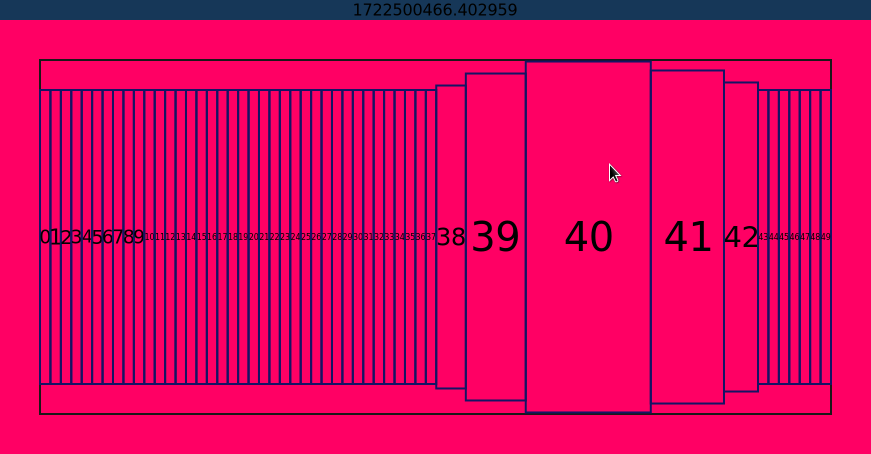
I want do continue work with this repo, but the rest of the time this month, I spent on my blog.
Micro.blog
I found out about Micro.blog and moved my blog to it.
Some reflections on Micro.blog: